Corruptions
Corruptions
Original Video
Spatial only
Spatiotemporal
Original Video
Spatial only
Spatiotemporal

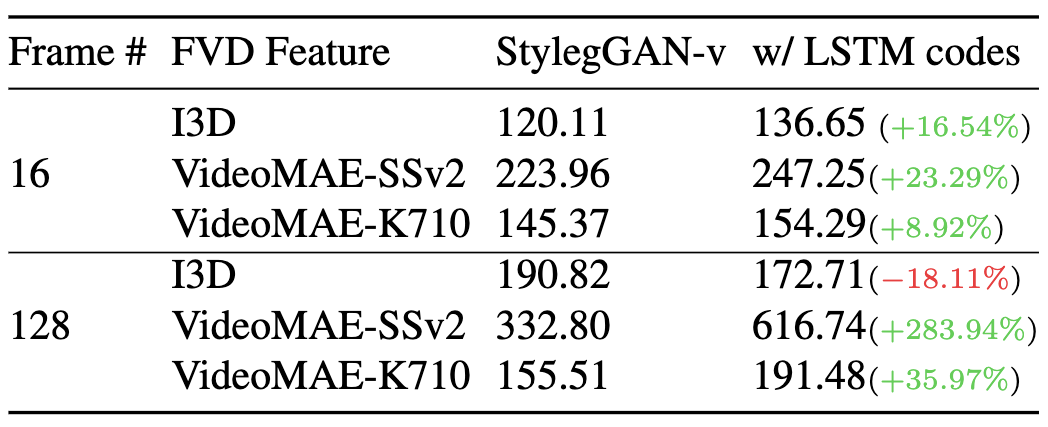
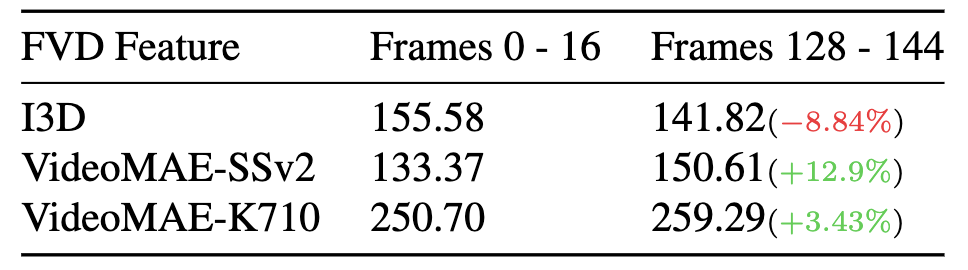
Quantify the temporal sensitivity.
We first develop ways to distort videos so that the frame quality deteriorates the same while the temporal quality
is either intact or significantly decreased.
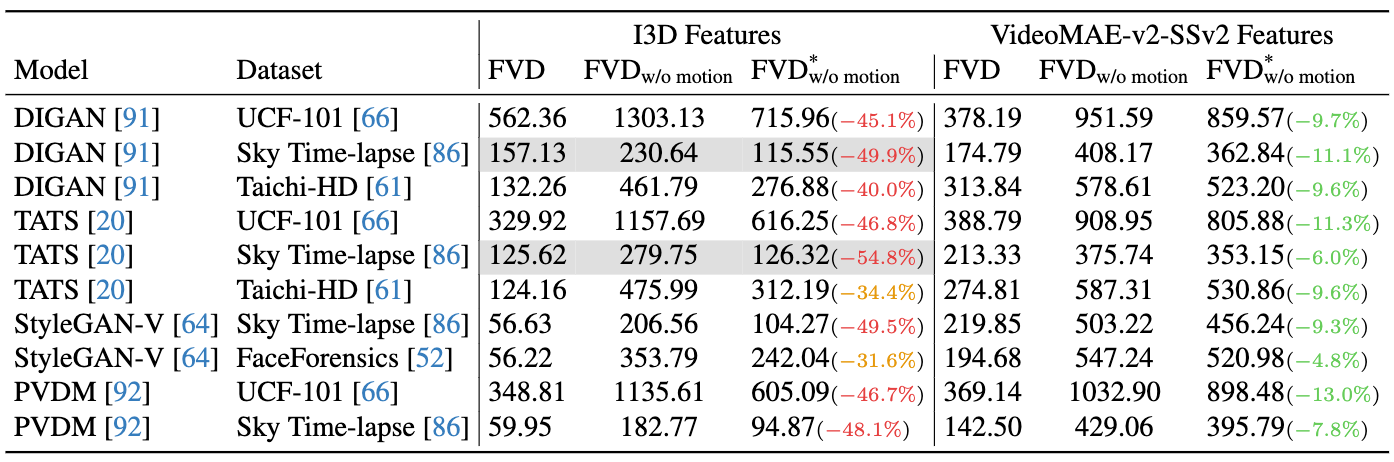
By comparing the FVD induced by the spatiotemporal corruption against the spatial corruption, we can analyze FVD's reletive
sensitivity to the temporal aspect.
We first verify our claim that the two distorted video sets share similar frame quality with the minimal FID difference,
shown in the table, between the spatial and spatiotemporal distortion across different datasets.
We then find that FVD sometimes fails to detect the temporal quality decrease induced by
spatiotemporal corruption. For example, the temporal inconsistency in the FaceForensics dataset only raises FVD by 3.6%.
To further grasp the significance of the FVD increase due to temporal inconsistency,
we compare it with the FVD computed using different models below.